前言
做题的时候碰到了挺多的ssrf类型的题目,这里做一个学习总结。
什么是ssrf
SSRF(Server-Side Request Forgery:服务器端请求伪造)是一种由攻击者构造形成并由服务端发起恶意请求的一个安全漏洞。进行SSRF的目的一般都是通过服务端来攻击黑客无法直接访问的内网系统。大致流程如下图所示: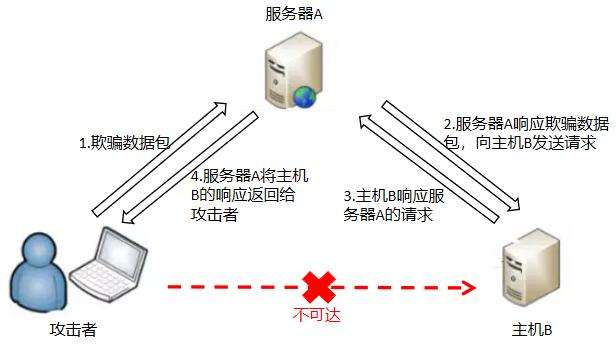
服务器A为web服务器,可以被攻击者访问,而主机B作为内网中其他服务器无法被访问。如果此时服务器A中的web服务存在ssrf漏洞,那么我们就可以通过服务器A发送请求头进行欺骗,达到获取主机B内容的目的。
漏洞产生原因
- file_get_contents():将整个文件或一个url所指向的文件读入一个字符串中。
- readfile():输出一个文件的内容。
- fsockopen():打开一个网络连接或者一个Unix 套接字连接。
- curl_exec():初始化一个新的会话,返回一个cURL句柄,供curl_setopt(),curl_exec()和curl_close() 函数使用。
- fopen():打开一个文件文件或者 URL。
- ……
上述函数的不当使用以及PHP原生类SoapClient在触发反序列化时都可导致SSRF。
漏洞危害
- 对外网、服务器所在内网、服务器本地进行端口扫描,获取一些服务的banner信息等。
- 攻击运行在内网或服务器本地的其他应用程序,如redis、mysql等。
- 对内网Web应用进行指纹识别,识别企业内部的资产信息。
- 攻击内外网的Web应用,主要是使用HTTP GET/POST请求就可以实现的攻击,如sql注入、文件上传等。
- 利用file协议读取服务器本地文件等。
- 进行跳板攻击等。
ssrf挖掘
- web功能
- 社交分享功能:获取超链接的标题等内容进行显示
- 转码服务:通过URL地址把原地址的网页内容调优使其适合手机屏幕浏览
- 在线翻译:给网址翻译对应网页的内容
- 图片加载/下载:例如富文本编辑器中的点击下载图片到本地、通过URL地址加载或下载图片
- 图片/文章收藏功能:主要其会取URL地址中title以及文本的内容作为显示以求一个好的用具体验
- 云服务厂商:它会远程执行一些命令来判断网站是否存活等,所以如果可以捕获相应的信息,就可以进行
- URL关键字
share、wap、url、link、src、source、target、u、3g、display、sourceURL、imageURL、domain等
利用方式
SSRF的利用主要就是读取内网文件、探测内网主机存活、扫描内网端口、攻击内网其他应用等,而这些利用的手法无一不与协议息息相关。
SSRF常用到的协议有:
- file协议: 在有回显的情况下,利用 file 协议可以读取任意文件的内容
- dict协议:泄露安装软件版本信息,查看端口,操作内网redis服务等
- http(s)协议:探测内网主机存活
- gopher协议:gopher支持发出GET、POST请求。可以先截获get请求包和post请求包,再构造成符合gopher协议的请求。gopher协议是ssrf利用中一个最强大的协议(俗称万能协议)。可用于反弹shell
file协议
构造如下payload,实现读取服务器上的本地文件及网站源码:
1 | ?url=file:///etc/passwd |
dict协议
我们可以利用dict协议构造payload查看内网主机上开放的端口及端口上运行服务的版本信息等,例如redis、http、ssh等:
1 | ?url=http://192.168.255.255:80/info |
出现什么的报错就说明该主机上有什么服务。
http(s)协议
先读取读取/etc/hosts、/proc/net/arp、/proc/net/fib_trie等文件获得目标主机的网络配置信息,以获得目标主机内网网段并进行爆破。内网段IP分为三类:
- A类:10.0.0.0 - 10.255.255.255
- B类:172.16.0.0 - 172.31.255.255
- C类:192.168.0.0 - 192.168.255.255
使用bp爆破或构建payload通过服务器发送请求检测内网存活主机:
1 | ?url=http://192.168.255.255 |
Gopher协议
Gopher协议支持发出GET、POST请求,是SSRF中最重要的利用协议之一。我们可以截获请求包,再修改构建成符合Gopher协议格式的payload,攻击面十分之广。
payload如下:
1 | ?url=gopher://<host>:<port>/<gopher-path>_TCP流 |
想要构造合法payload,可以利用下面的脚本进行改写:
1 | import urllib.parse |
要注意:
- 问号需要转码为URL编码,也就是%3f
- 回车换行要变为%0d%0a,但如果直接用工具转
- 在HTTP包的最后要加%0d%0a,代表消息结束
bypass
基本身份认证绕过
如果目标代码限制访问的域名只能为http://www.hack.com,那么我们可以采用HTTP基本身份认证的方式绕过。即@:http://www.xxx.com@www.mrl64.com302跳转
如果要求从本地访问,我们可以使用xip.io,当访问这个服务的任意子域名的时候,都会重定向到这个子域名。例如,当我们访问http://127.0.0.1.xip.io/flag.php时,实际访问的是http://127.0.0.1/1.php。这样的网址还有http://nip.io和http://sslip.io。
或者使用短地址,https://4m.cn/对应的短地址即为本地,例如 https://4m.cn/FjOdQ就会自动302跳转到http://127.0.0.1/flag.php上。
- 进制绕过
利用ip地址的进制变化,绕过,这里提供一个在线工具与脚本:
IP地址进制转化
脚本:
1 | <?php |
还有其他指向本地的地址:
1 | http://localhost/ |
- 目录穿越
PHP的file_get_contents()在遇到不认识的协议头时候会将这个协议头当做文件夹,造成目录穿越漏洞,这个方法可以在SSRF的众多协议被禁止且只能使用它规定的某些协议的情况下来进行读取文件。
例如:
1 | ?url=httpssss://../../../../etc/passwd |
- url解析
(1)readfile和parse_url函数的解析差异
如果后端用parse_url限制我们传递url的端口,例如限定了80,而我们想要读取9999端口中的内容,我们可以这样构建payload:1
?url=http://127.0.0.1:9999:80/
这是因为readfile()获取的端口是最后冒号前面的一部分,而parse_url()获取的则是最后冒号后面的的端口,利用这种差异的不同,从而绕过WAF。
同样这两个函数对host的解析也是不同的,readfile()获取的是@号后面一部分,而parse_url()获取的则是@号前面的一部分,利用这种差异的不同,我们可以绕过题目中parse_url()函数对指定host的限制。
(2)curl和parse_url的解析差异
这两个函数主要针对host解析上的差异,curl()解析的是第一个@后面的网址,而parse_url()解析的是第二个@后面的网址。利用这个原理我们可以绕过题目中parse_url()对指定host的限制。
1 | ?url=http://foo@hack.com:80@mrl64.com |
总结
SSRF也是web中的一个经典考点了,通过SSRF可以对内网的Redis、FastCGI、Mysql等发起攻击。之后遇到新的题型会继续补充。